
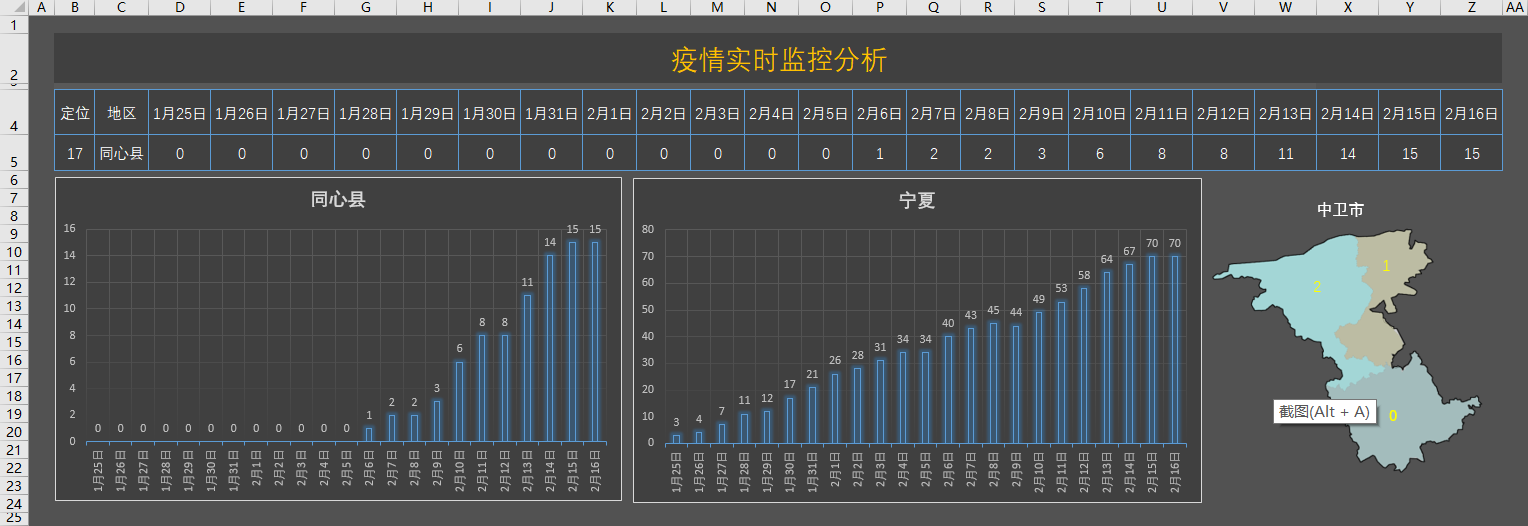
Excel实现,套用公式,未用VBA,右侧地图用图片,如果要做成数据地图可参考https://www.sohu.com/a/307228212_817016
SVG地图获取不用那么麻烦,阿里云官网就有
http://datav.aliyun.com/tools/atlas
原教程第三步有点问题:
用excel导入emf的文件,然后ungroup这个地图变成freeform的图形,如下图。
这地方应改成:
用excel导入wmf的文件,然后取消组合这个地图变成freeform的图形,如下图。
所谓导入其实就是插入wmf图片,不是emf。
数据获取自己到官网查就行了,不管是百度还是腾讯,数据都只是到市,县区的数据还是得到官网查询。各地方卫健委的官网上可以查到数据。
宁夏卫健委:http://wsjkw.nx.gov.cn/yqfkdt/yqsd1.htm
宁夏的数据还可以从宁夏新闻网获取,这个有时候比官网更新的早。
http://www.nxnews.net/zt/2020/2020kjfy/2020nxyqb/
如果嫌麻烦又怕眼睛看花,可以用下面python脚本获取宁夏的详细数据,两个代码获取到的数据是一致的,只是实现方式有点区别。
代码一
import requests
import re
import time
from bs4 import BeautifulSoup
def UpdateUrl(date = time.strftime("%Y-%m-%d")):
url = "http://www.nxnews.net/zt/2020/2020kjfy/2020nxyqb/"
respons = requests.get(url)
respons.encoding = 'utf-8'
bs = BeautifulSoup(respons.text, "html.parser")
# print(bs.title.get_text())
item = bs.find(name='tr')
isupdate = item.get_text().find(time.strftime("%Y-%m-%d"))
if isupdate != -1:
el = item.find(name='a')
#text = el.get_text()
href = re.sub(r'[^a-zA-Z0-9,\/:._]+', '', el.get('href'))
#print(text)
#print(href)
return href
else:
#print("今日未更新!")
return ''
def parData(url):
data = {
"银川市": 0,
"兴庆区": 0,
"西夏区": 0,
"金凤区": 0,
"永宁县": 0,
"贺兰县": 0,
"灵武市": 0,
"石嘴山市": 0,
"大武口区": 0,
"惠农区": 0,
"平罗县": 0,
"吴忠市": 0,
"利通区": 0,
"红寺堡区": 0,
"盐池县": 0,
"同心县": 0,
"青铜峡市": 0,
"固原市": 0,
"原州区": 0,
"西吉县": 0,
"隆德县": 0,
"泾源县": 0,
"彭阳县": 0,
"中卫市": 0,
"沙坡头区": 0,
"中宁县": 0,
"海原县": 0,
"宁东": 0
}
respons = requests.get(url)
respons.encoding = 'utf-8'
bs = BeautifulSoup(respons.text, "html.parser")
# print(bs.title.get_text())
item = bs.find('div',class_='article')
item = item.find_all('p')
item = item[3]
#print(item[3])
#item.get_text()
for k in data.keys():
#data[k] = re.match(r'银川市[0-9]+例',item.get_text()).group()[len(key)-1:-1]
reg_txt = k + '[0-9]+例'
#print(reg_txt)
res = re.search(reg_txt,item.get_text())
if not res is None:
#print(res)
data[k] = res.group(0)[len(k):-1]
return data
if __name__=="__main__":
url= UpdateUrl()
if url != '':
print(url)
data = parData(url)
for k in data.keys():
print(k + "\t" + str(data[k]))
else:
print("今日尚未更新!")
代码二
import requests
import re
import time
from bs4 import BeautifulSoup
def UpdateUrl(date = time.strftime("%Y-%m-%d")):
url = "http://www.nxnews.net/zt/2020/2020kjfy/2020nxyqb/"
respons = requests.get(url)
respons.encoding = 'utf-8'
bs = BeautifulSoup(respons.text, "html.parser")
# print(bs.title.get_text())
item = bs.find(name='tr')
isupdate = item.get_text().find(time.strftime("%Y-%m-%d"))
if isupdate != -1:
el = item.find(name='a')
#text = el.get_text()
href = re.sub(r'[^a-zA-Z0-9,\/:._]+', '', el.get('href'))
#print(text)
#print(href)
return href
else:
#print("今日未更新!")
return ''
def parData(url):
data = {
"银川市": 0,
"兴庆区": 0,
"西夏区": 0,
"金凤区": 0,
"永宁县": 0,
"贺兰县": 0,
"灵武市": 0,
"石嘴山市": 0,
"大武口区": 0,
"惠农区": 0,
"平罗县": 0,
"吴忠市": 0,
"利通区": 0,
"红寺堡区": 0,
"盐池县": 0,
"同心县": 0,
"青铜峡市": 0,
"固原市": 0,
"原州区": 0,
"西吉县": 0,
"隆德县": 0,
"泾源县": 0,
"彭阳县": 0,
"中卫市": 0,
"沙坡头区": 0,
"中宁县": 0,
"海原县": 0,
"宁东": 0
}
respons = requests.get(url)
respons.encoding = 'utf-8'
bs = BeautifulSoup(respons.text, "html.parser")
# print(bs.title.get_text())
item = bs.find('div',class_='article')
#item.get_text()
qz_pos = re.search('累计报告',item.get_text())
#print(qz_pos.start())
for k in data.keys():
#data[k] = re.match(r'银川市[0-9]+例',item.get_text()).group()[len(key)-1:-1]
reg_txt = k + '[0-9]+例'
#print(reg_txt)
res = re.finditer(reg_txt,item.get_text())
if res :
for t in res:
#print(t)
if t.start() > qz_pos.start() : #小于新增
data[k] = t.group()[len(k):-1]
print(t.group())
break
#print(res)
return data
if __name__=="__main__":
url= UpdateUrl()
if url != '':
print(url)
data = parData(url)
for k in data.keys():
print(k + "\t" + str(data[k]))
else:
print("今日尚未更新!")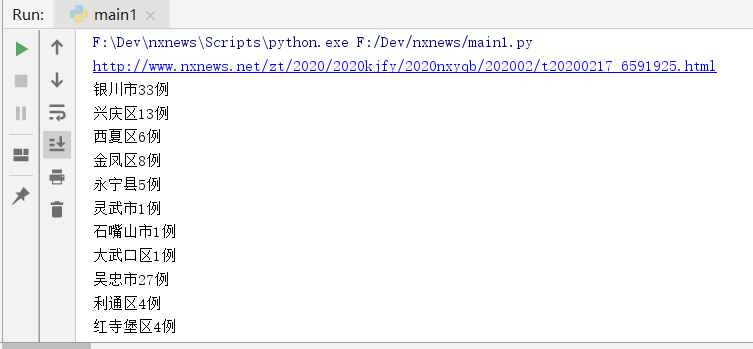
还不快抢沙发