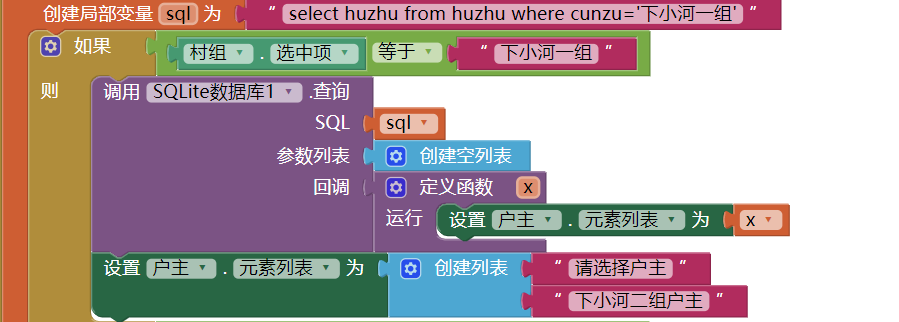
SQlite数据库查询

不同公式实现通过身份证号码判断性别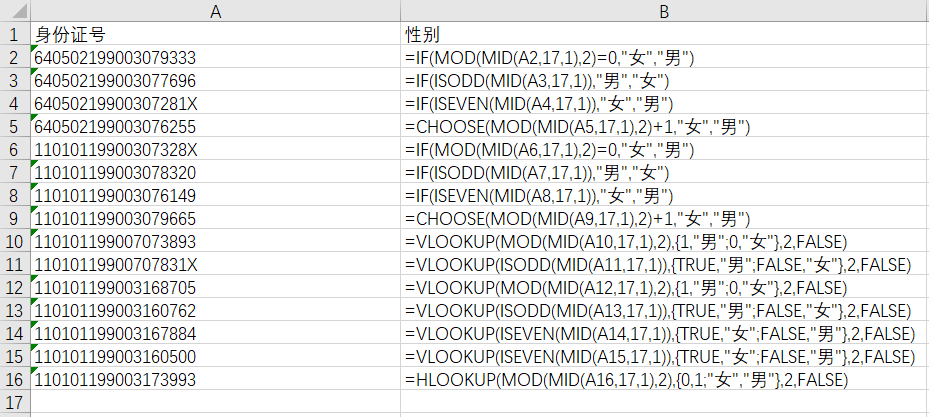
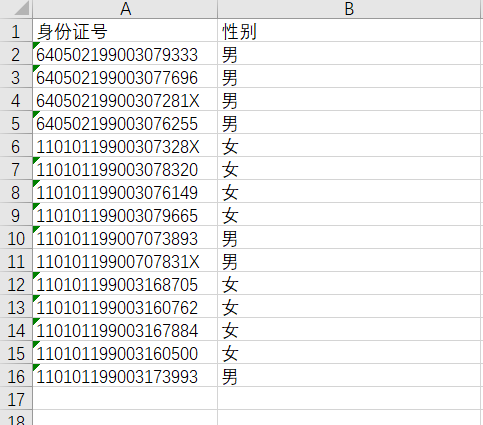
=IF(MOD(MID(A2,17,1),2)=0,"女","男")
=IF(ISODD(MID(A3,17,1)),"男","女")
=IF(ISEVEN(MID(A4,17,1)),"女","男")
=CHOOSE(MOD(MID(A5,17,1),2)+1,"女","男")
=IF(MOD(MID(A6,17,1),2)=0,"女","男")
=IF(ISODD(MID(A7,17,1)),"男","女")
=IF(ISEVEN(MID(A8,17,1)),"女","男")
=CHOOSE(MOD(MID(A9,17,1),2)+1,"女","男")
=VLOOKUP(MOD(MID(A10,17,1),2),{1,"男";0,"女"},2,FALSE)
=VLOOKUP(ISODD(MID(A11,17,1)),{TRUE,"男";FALSE,"女"},2,FALSE)
=VLOOKUP(MOD(MID(A12,17,1),2),{1,"男";0,"女"},2,FALSE)
=VLOOKUP(ISODD(MID(A13,17,1)),{TRUE,"男";FALSE,"女"},2,FALSE)
=VLOOKUP(ISEVEN(MID(A14,17,1)),{TRUE,"女";FALSE,"男"},2,FALSE)
=VLOOKUP(ISEVEN(MID(A15,17,1)),{TRUE,"女";FALSE,"男"},2,FALSE)
=HLOOKUP(MOD(MID(A16,17,1),2),{0,1;"女","男"},2,FALSE)
import tkinter
print(tkinter.TkVersion)疫情面前,扶贫不能停步
能不手填的坚决不手填,一是为防止出错,二是提高效率,地点选择三级联动。
采集表 .zip
python汇总数据
import os
import openpyxl
import re
fList = []
def searchfile(path):
for item in os.listdir(path):
if os.path.isdir(os.path.join(path, item)):
searchfile(os.path.join(path, item))
else:
if '.xlsx' in item:
# print(path + item)
fList.append(path + '\\' + item)
if __name__ == "__main__":
path = r'C:\Users\dell\Desktop\数据采集\已采集'
# 创建汇总文件
wb = openpyxl.Workbook()
# sheet1 户信息
Sheet1 = wb.create_sheet(index=0, title="户信息")
title1 = ["序号", "户编号", "村组", "户主", "联系电话", "产业帮扶需求", "备注"]
for i in range(len(title1)):
Sheet1.cell(1, i + 1).value = title1[i]
# sheet2 个人信息
Sheet2 = wb.create_sheet(index=1, title="个人信息")
title2 = ["序号", "户编号", "村组", "与户主关系", "姓名", "证件号码", "外出时间(已外出务工人口)",
"务工地点(已外出务工人口)", "务工地点(计划外出务工人员)", "就业服务需求(计划外出务工人员)", "备注"]
for i in range(len(title2)):
Sheet2.cell(1, i + 1).value = title2[i]
searchfile(path)
index = 0
for i, file in enumerate(fList):
print(file)
(filepath, tempfilename) = os.path.split(file)
(filename, extension) = os.path.splitext(tempfilename)
hbh = filename.split("-") #从文件名中获取户编号
#print(hbh[0])
wb_r = openpyxl.load_workbook(file, read_only=True)
ws_r = wb_r.active
# 汇总户信息
Sheet1.cell(2 + i, 1).value = i + 1 # 序号
Sheet1.cell(2 + i, 2).value = hbh[0] # 户编号
Sheet1.cell(2 + i, 3).value = ws_r['C3'].value # 村组
Sheet1.cell(2 + i, 4).value = ws_r['C4'].value # 户主姓名
Sheet1.cell(2 + i, 5).value = ws_r['E4'].value # 联系电话
Sheet1.cell(2 + i, 6).value = ws_r['C5'].value # 产业帮扶需求
#re.findall('(book+)', 'mebookbookme')
bz = ""
rst = re.findall('([ √)]+)', ws_r['C5'].value)
s1 = rst[0].find("√")
if s1>0 :
bz = "√,"
else:
bz = "×,"
s2 = rst[1].find("√")
if s2>0 :
bz = bz + "√,"
else:
bz = bz + "×,"
s3 = rst[2].find("√")
if s3>0 :
bz = bz + "√,"
else:
bz = bz + "×,"
s4 = rst[3].find("√")
if s4>0 :
bz = bz + "√,"
else:
bz = bz + "×,"
s5 = rst[4].find("√")
if s5>0 :
bz = bz + "√"
else:
bz = bz + "×"
Sheet1.cell(2 + i, 7).value = bz # 备注
# 汇总个人信息
for j in range(5):
if ws_r.cell(8 + 4*j, 2).value == None :
break
Sheet2.cell(2 + index, 1).value = index + 1 # 序号
Sheet2.cell(2 + index, 2).value = hbh[0] # 户编号
Sheet2.cell(2 + index, 3).value = ws_r['C3'].value # 村组
Sheet2.cell(2 + index, 4).value = ws_r.cell(8 + 4*j, 1).value # 与户主关系
Sheet2.cell(2 + index, 5).value = ws_r.cell(8 + 4*j, 2).value # 姓名
Sheet2.cell(2 + index, 6).value = ws_r.cell(8 + 4*j, 3).value # 证件号码
Sheet2.cell(2 + index, 7).number_format='yyyy-mm-dd'
Sheet2.cell(2 + index, 7).value = ws_r.cell(8 + 4*j, 4).value # 外出时间(已外出务工人口)
Sheet2.cell(2 + index, 8).value = ws_r.cell(8 + 4*j, 5).value # 务工地点(已外出务工人口)
Sheet2.cell(2 + index, 9).value = ws_r.cell(8 + 4*j, 6).value # 务工地点(计划外出务工人员)
str1 = ws_r.cell(8 + 4 *j , 7).value
str2 = ws_r.cell(9 + 4 * j, 7).value
str3 = ws_r.cell(10 + 4 * j, 7).value
str4 = ws_r.cell(11 + 4 * j, 7).value
str = str1 + "\n" + str2 + "\n" + str3 + "\n" + str4
Sheet2.cell(2 + index, 10).alignment = openpyxl.styles.Alignment(wrapText=True)
Sheet2.cell(2 + index, 10).value = str # # 就业服务需求(计划外出务工人员)
bz = ""
s1 = str1.find("√")
if s1 > 0:
bz = "√,"
else:
bz = "×,"
s2 = str2.find("√")
if s2 > 0:
bz = bz + "√,"
else:
bz = bz + "×,"
s3 = str3.find("√")
if s3 > 0:
bz = bz + "√,"
else:
bz = bz + "×,"
s4 = str4.find("√")
if s4 > 0:
bz = bz + "√"
else:
bz = bz + "×"
Sheet2.cell(2 + index, 11).value = bz # 备注
index = index + 1
wb.save('汇总.xlsx')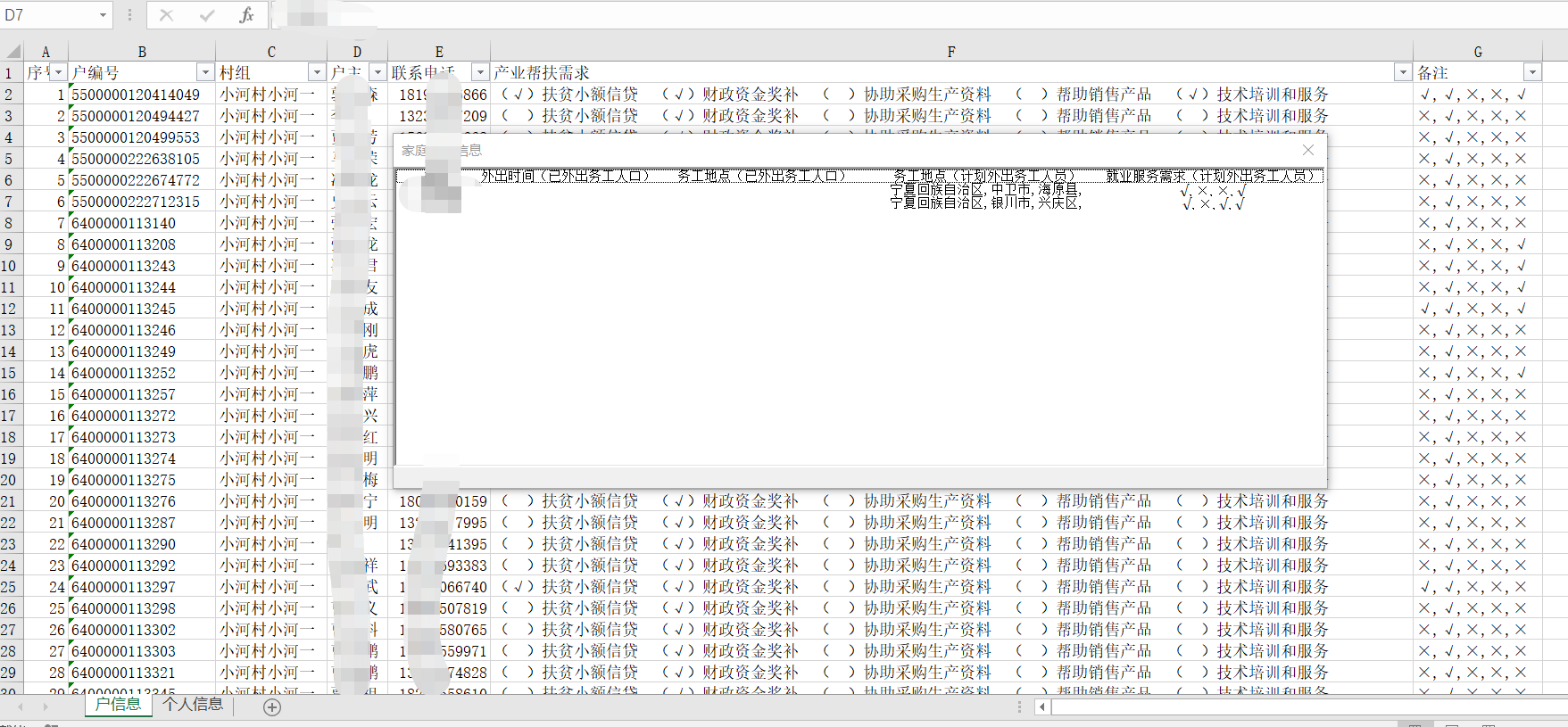

数据网址:
http://www.mca.gov.cn/article/sj/xzqh/2019/2019/201912251506.html
粘贴到Excel中整理(查找替换将多余的空格替换掉),增加辅助列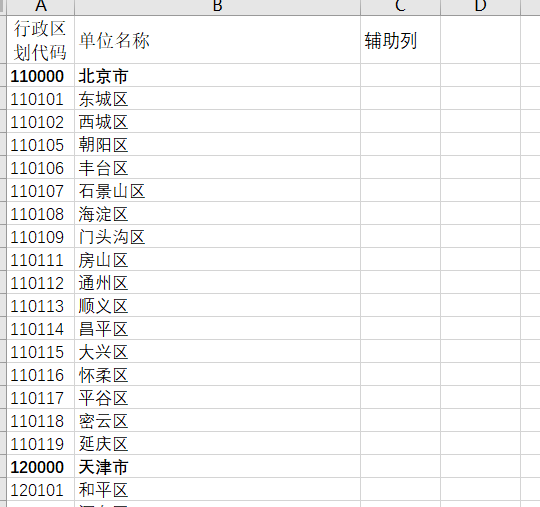
辅助列收入公示=MID(A2,5,2)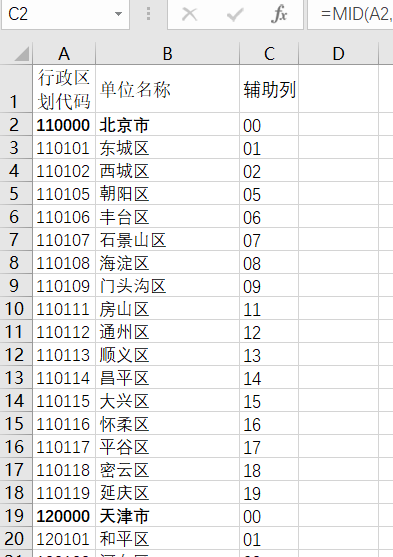
保留直辖市数据(辅助列数据删除),数据筛选,将末尾是01~09的删除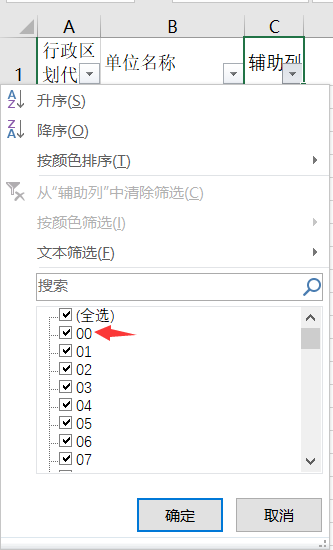
辅助列输入公示=MID(A2,3,4)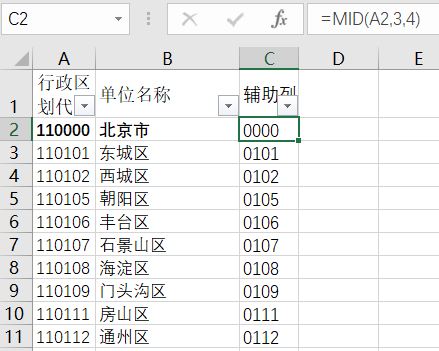
筛选出末尾是0000的数据,将单位名称粘贴出来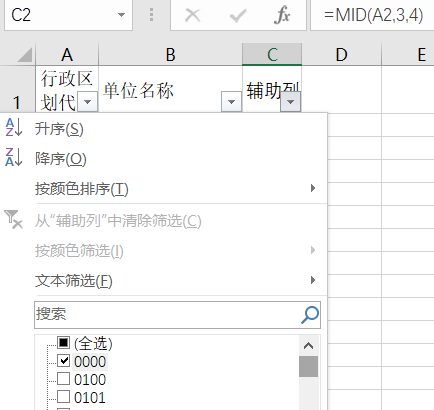
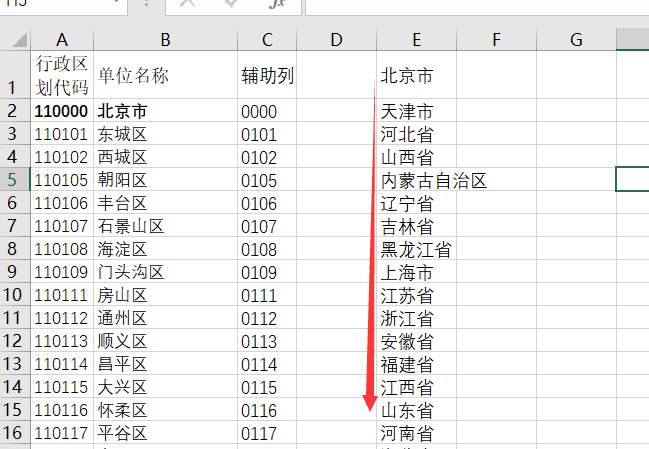
在一级菜单处设置数据有效性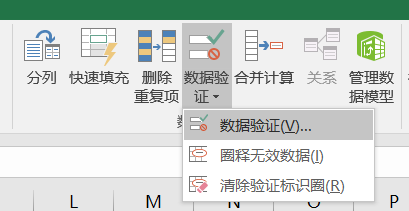
红色地方是刚才制作的一级数据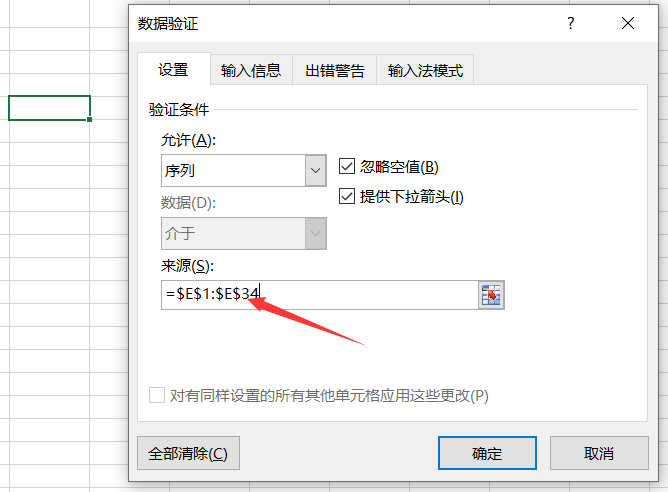
二级菜单处同理制作数据有效性
辅助列输入公示=MID(A2,5,2)
在一级菜单右侧打开数据有效性,输入公示=INDIRECT("B"&(MATCH(H5,B:B,0)+1)&":B"&(MATCH(H5,B:B,0)+COUNTIFS(C:C,">" & vlookup(H5,B:C,2,false),C:C,"<" & (vlookup(H5,B:C,2,false)+1000))))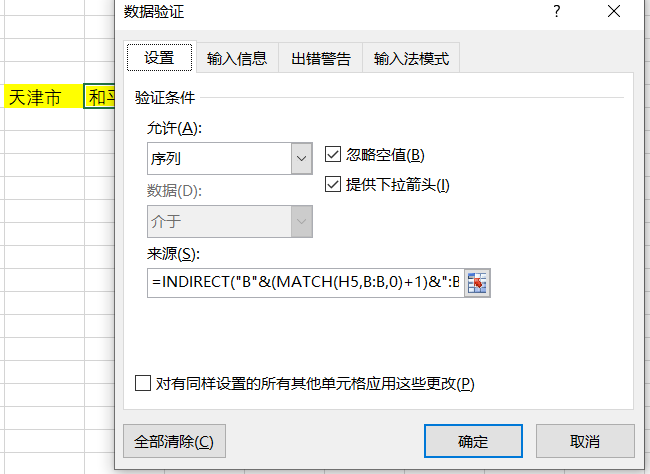
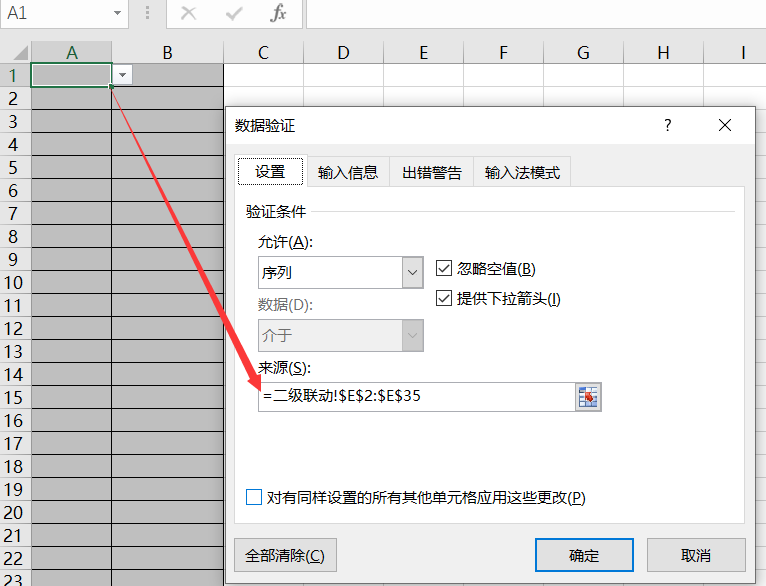
直接粘贴使用公示=二级联动!$E$2:$E$35
红色部分改为一级菜单单元格,公示=INDIRECT("二级联动!" & VLOOKUP(A1,二级联动!$E$1:$J$35,6,FALSE))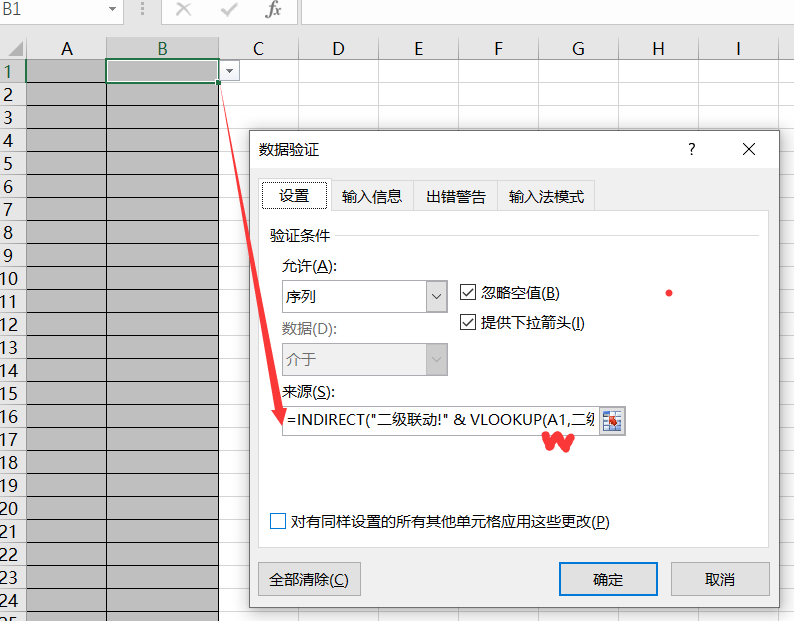
剩下单元格拉下填充即可!
二级联动案例.xlsx